我们通常认为爬行预算是超出我们控制范围的。或者更确切地说,我们通常不会想到爬行预算。然而,随着我们的网站越来越大,爬行预算成为我们在搜索领域存在的主要影响因素。在这篇文章中,我将讨论爬行预算的重要性,并分享一些管理网站爬行预算的实用建议。
内容什么是爬行预算?为什么爬行预算如此重要?你应该担心你的爬行预算吗?如何优化你的爬行预算?1. 向搜索控制台2提交一个站点地图。解决爬行冲突隐藏不应该被抓取的页面4。隐藏不必要的资源。避免长重定向链6。管理动态url解决重复内容问题优化网站结构额外好处:请求索引最后的想法什么是爬行预算?
爬行预算是谷歌愿意花在爬行你的网站上的资源数量。可以这么说,你的爬行预算等于每天爬行的页面数,但这并不完全正确。有些页面比其他页面消耗更多的资源,因此即使预算保持不变,爬行页面的数量也会有所不同。在分配爬行预算时,谷歌通常会考虑四件事:你的网站的受欢迎程度、更新率、页面数量和处理爬行的能力。但是,即使它是一个复杂的算法,您仍然可以干预并帮助谷歌管理它抓取您的网站的方式。为什么爬行预算很重要?
爬行预算决定了你的页面在搜索中出现的速度。这里的主要问题是爬行预算和网站更新率之间可能不匹配。如果出现这种情况,从创建或更新页面到在搜索中出现页面的时间间隔将会越来越长。你没有得到足够的爬行预算的一个可能的原因是谷歌不认为你的网站足够重要。所以它要么是垃圾邮件,要么提供非常糟糕的用户体验,或者两者兼而有之。在这种情况下,你除了发布更好的内容并等待你的声誉提高外,没有什么可以做的。你没有得到足够的爬行预算的另一个可能的原因是你的网站充满了爬行陷阱。有一些技术问题,爬虫可能会陷入循环,无法找到您的页面,或以其他方式阻止访问您的网站。在这种情况下,你可以做一些事情来显著提高你的爬行能力,我们将在下面进一步讨论。你应该担心你的爬行预算吗?如果你运行的是一个更新频率很高(从一天一次到一周一次)的大型或中型网站,爬行预算可能会成为一个问题。在这种情况下,缺乏爬行预算可能会造成永久的索引滞后。当发布一个新网站或重新设计一个旧网站时,这也可能是一个问题,因为很多变化都在快速发生。尽管这种爬行延迟最终会自行解决。不管网站的大小,最好至少审计一次可能的爬行问题。如果你运行的是一个大型网站,那么现在就做,如果你运行的是一个较小的网站,那么就把它放在你的待办事项清单上。
如何优化你的爬行预算?有相当多的事情你应该(或不应该)做,以鼓励搜索蜘蛛消费更多的页面,你的网站更频繁。这里有一个行动列表,可以最大化你的爬行预算:
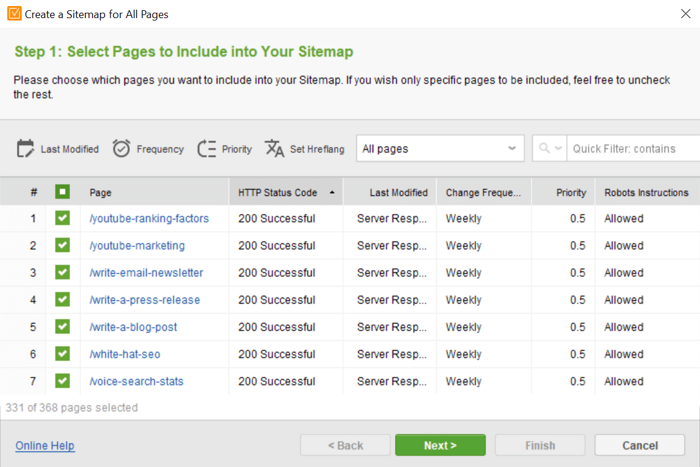
一个站点地图是一个文档,包含所有你想要在搜索中被抓取和索引的页面。如果没有站点地图,谷歌将不得不发现站点上内部链接后面的页面。通过这种方式,谷歌将需要一段时间来理解您的网站的范围,并决定哪些发现的页面应该被索引,哪些不应该被索引。有了网站地图,谷歌就能确切地知道你的网站有多大,以及哪些页面应该被编入索引。甚至还有一个n选项告诉谷歌每个页面的优先级是什么以及更新的频率。有了这些可用的信息,谷歌可以为您的网站设计最合适的爬行模式。注意:谷歌将网站地图视为推荐,而不是义务,这一点很重要——它可以随意忽略你的网站地图,为你的网站选择不同的爬行模式。现在,有很多方法可以创建站点地图。如果您使用的是CMS平台,如Shopify,那么您的站点地图可能会自动生成,并已在yourwebsite.com/sitemap.xml上提供。其他CMS平台肯定会有SEO插件提供站点地图服务。如果你有一个定制的网站,或者你不想用额外的插件给你的网站增加负担,你可以使用网站审计器来生成和管理你的网站地图。进入网站结构>页面>网站工具> Sitemap,你会得到一个完整的网站页面列表。您可以按HTTP状态对页面进行排序,排除那些无法访问的页面,还可以更改页面的优先级、更新速率和最后修改日期:

当您完成编辑站点地图时,单击下一步并选择下载文档的选项-它将自动转换为适当的站点地图协议。然后你可以添加网站地图到你的网站,以及提交它到谷歌搜索控制台:

这也是常见的有几个网站地图为同一网站。有时这样做是为了方便——这样更容易管理主题相似的页面。其他时候,这是出于需要——网站地图文档有50K页的限制,如果你有一个更大的网站,你被迫创建多个网站地图,以覆盖所有的网站。
2。一个常见的爬行问题是谷歌认为页面应该被爬行,但它不能被访问。在本例中,可能会发生以下两种情况之一:
选项1。页面不应该被抓取,它被错误地提交到谷歌。在这种情况下,您必须通过从站点地图中删除该页或删除到该页的内部链接或同时删除两者来取消提交该页。
选项2。应该抓取页面,并错误地拒绝访问。在这种情况下,您应该检查是什么阻止了访问(robots.txt, 4xx, 5xx,重定向错误),并相应地修复问题。不管是哪种情况,这些混合信号迫使谷歌进入死胡同,不必要地浪费了您的爬行预算。发现和解决这些问题的最佳方法是在谷歌搜索控制台中检查覆盖率报告。Error选项卡专门用于抓取冲突,并提供错误数量、错误类型和受影响页面的列表:
 3。另一种类型的爬取冲突是错误地爬取页面并建立索引。这显然是在浪费您的爬行预算,但更重要的是,这也可能是一个安全问题。如果您使用了错误的方法来阻止爬行,这可能意味着您的一些私有页面被索引,现在可以公开使用。要找到这样的页面,最好转到谷歌搜索控制台和它的覆盖率报告。切换到Valid with warning选项卡,您将得到爬行的页面数量,以及可疑的问题和受影响的页面列表:
3。另一种类型的爬取冲突是错误地爬取页面并建立索引。这显然是在浪费您的爬行预算,但更重要的是,这也可能是一个安全问题。如果您使用了错误的方法来阻止爬行,这可能意味着您的一些私有页面被索引,现在可以公开使用。要找到这样的页面,最好转到谷歌搜索控制台和它的覆盖率报告。切换到Valid with warning选项卡,您将得到爬行的页面数量,以及可疑的问题和受影响的页面列表:

这些页面最常见的问题是它们被robots.txt文件阻塞。对于网站管理员来说,使用robots.txt来阻止页面被索引仍然很常见。同时,谷歌将robots.txt指令作为推荐,可能决定在搜索中仍然显示“被屏蔽”的页面。要解决这些问题,请检查页面列表,并决定是否要为它们建立索引。如果没有,你必须使用noindex元标记来完全阻止爬虫,然后通过索引> Removals > New re从搜索中删除页面追求。如果是,必须从robots.txt文件的disallow指令中删除该页。
4。通过告诉谷歌忽略非必要的资源,您可以节省大量的爬行预算。像动图、视频和图像这样的东西会占用大量内存,但通常用于装饰或娱乐,对于理解页面的内容可能并不重要。要阻止谷歌抓取这些非必要的资源,请禁用robots.txt文件中的这些资源。你可以通过名称禁止单个资源:
User-agent: * disallow: /images/filename.jpg
你也可以禁止整个文件类型:
User-agent: * disallow: /*.gif$
如果一行中301和302重定向的数量不合理,搜索引擎将在某个时刻停止跟踪重定向,目标页面可能不会被抓取。更重要的是,每个重定向的URL都是对你的“单位”爬行预算的浪费。确保你使用重定向在一行中不超过两次,并且只在绝对必要的情况下使用。要获得带有重定向的页面的完整列表,启动网站审计器并进入网站结构>网站审计>重定向。单击带有302重定向的页面和带有301重定向的页面,可获得重定向页面的完整列表。单击具有长重定向链的页面,可获得超过2个重定向的url列表:
 6。管理动态url
6。管理动态url
流行的内容管理系统生成大量动态url,所有这些url都指向同一个页面。默认情况下,搜索引擎机器人会将这些url视为单独的页面。结果,你可能既浪费了你的爬行预算,也可能滋生重复的内容问题。如果您的网站引擎或CMS在URL中添加了不影响页面内容的参数,请确保您通过在您的谷歌搜索控制台帐户中的遗留工具和报告> URL参数:

中管理这些参数,让谷歌知道这一点。在那里,您可以单击任何参数旁边的编辑,并决定页面是否允许搜索用户查看。
7。解决重复内容问题
重复内容意味着有两个或两个以上的页面,内容基本相似。这种情况的发生有多种原因。动态url是其中之一,但也包括A/B测试,www/非www版本,http/https版本,内容联合,以及一些CMS平台的细节。复制内容的问题在于,你会浪费双倍的预算去抓取相同的内容。要解决重复的内容问题,首先必须找到重复的页面。一种方法是在网站审计器工具中寻找重复的标题和元描述:

标题,特别是元描述是具有相同内容的页面的一个很好的指示器。如果您发现任何确实相似的页面,那么您必须确定哪一个是主要的,哪一个是副本。现在转到复制页面,并将此代码添加到部分:
其中URL是主页的地址。
通过这种方式,谷歌将忽略重复的页面,而专注于抓取主页。
8。优化网站结构
虽然内部链接与你的爬行预算没有直接关系,谷歌说,直接从你的主页链接的页面可能被认为更重要,更频繁地爬行。一般来说,保持站点的重要区域与任何页面之间的距离不超过3次点击是很好的建议。在你的网站菜单或页脚中包含最重要的页面和类别。对于更大的网站,如博客和电子商务网站,相关文章/产品和特色文章/产品的部分可以极大地帮助用户和搜索引擎把你的登陆页放在那里。如果您需要详细的说明,我强烈建议您阅读这个内部链接指南。如果你刚刚发布或更新了一个惊人的,只是等不及谷歌抓取它,通过使用谷歌搜索控制台的请求索引功能切断行。你所要做的就是将你的URL粘贴到顶部的URL检查字段中,点击回车,然后请求索引:

即使页面已经被索引了,你也可以这样做,但你只是更新了它:

这个特性的效果不是立竿一影的。和谷歌一样,这个请求更像是一个非常礼貌的推荐。正如你所看到的,SEO不仅仅是关于“有价值的内容”和“有信誉的链接”。当你的网站的正面看起来很漂亮的时候,也许是时候下到地下室去找一些蜘蛛了——这肯定会在提高你的网站的搜索性能方面产生奇迹。现在您已经拥有了驯服搜索引擎蜘蛛所需的所有工具和知识,继续在您自己的网站上测试它,并请在评论中分享结果!